Hierarchical Cross-Modal Talking Face Generation with Dynamic Pixel-Wise Loss
CVPR2019
A cascade GAN approach to generate talking face video.
Robust to different face shapes, view angles, facial charateristics. noisy audio conditions.
audio to high-level structure(facial landmarks) and then to generate video frames.
Compared to a direct audio-to-image approach, 우리의 캐스캐이드 접근법은 가짜 연관성을 피한다.
가짜 연관성이란 음성 내용과 무관한 오디오 비주얼 신호 사이의 연관성을 말하는 것이다.
사람은 시간 불연속과 순간 아티팩트에 민감하다. 이런 픽셀 지터링을 피하고 네트웍이 오디오 비주얼 연관된 지역에 집중하게 하기위해 우리는 dynamically adjustable pixel-wise loss과 attention mechanism을 사용한다.
얼굴음직임과 잘 싱크된 더 날카로운 이미지 생성을 위해 새로운 리그레션 기반 분류 구조를 제안한다.
이 분류기는 프레임 레벨과 시퀀스 레벨의 정보를 고려한다.
audio-to-video generation
[28] Synthesizing obama: learning lip sync from audio. Graph 2017.
[3] You said that? BMVC 2017.
[2] Deep cross modal audio-visual generation. Multimedia workshop 2017.
text-to-video generation
[23] Attentive semantic video generation using captions. ICCV 2017.
[19] Video generation from text. AAAI 2018.
skeleton-to-image/video generation
[21] Pose guided person image generation. NIPS 2017.
[7] Gp-gan: Gender preserving gan for synthesizing faces from landmarks.
application
for hearing-impaired people, virtual charatoer with cynchronized facial movements.
[3] encoder-decoder structure generate one image from 0.35 second audio.
[27] Talking face generation by conditional recurrent adversarial network. CoRR 2018.
RNN for feature extraction, each frame generated independently.
in this paper we propose a novel temporal GAN structure. multi-modal convolutional RNN based(MMCRNN).
photo-realistic talking face generation methods
[3], [27], [28]
[12] Talking face generation by adversarially disentangled audio-visual representation. AAAI 2019.
[1] Lip movements generation at a glance. ECCV 2018.
[35] X2face: A network for controlling face generation using images, audio, and pose codes. ECCV 2018.
algorithm
1. estimate facial landmarks from input audio
2. generates pixel variations in image space conditioned on generated landmarks.
랜드마크 미드 특징을 사용하여 불필요한 가시적 움지임을 회피뿐만아니라 오디오 비주얼 연관에 집중할 수 있게 어테션을 사용하였다.
[8] Generating talking face landmarks from speech. LVA/ICA 2018.
ilrrelevant visual dynamics are removed in the training process by normalizing and identity removing the facial landmarks. audio-driven facial landmarks generation work.
popular dataset
GRID, LRW, VoxCeleb, TCD.
contributions
1. cascade network to reduce sound-irrelevant visual dynamics in image space.
2. dynamically adjustable pixel-wise loss along with an attention mechanism. alleviate temporal discontinuities and aritifacts.
3. regression based discriminator to improve the audio-visual synchronization and to smooth the facial movement transition.
Talking Face Synthesizing
specific person
[11] Vdub: Modifying face video of actors for plausible visual alignment to a dubbed audio track. Graph 2015.
[9] Photo-real talking head with deep bidirectional LSTM. ICASSP 2015. [28] Obama.
Obama 가장 잘 매칭되는 입모양을 디비에서 오디오비주얼 특징의 코릴레이션으로 획득하고 합성한다.
하지만 이방법은 많은 양의 디비를 요한다.
generate arbitrary faces from arbitrary input audio.
GAN encoder-decoder structure and the data-driven training strategy.
[27] Talking face generation by conditional recurrent adversarial network. CoRR 2018.
[4] Lip reading in the wild. ACCV 2016.
[1] Lip movements generation at a glance. ECCV 2018.
[12] Talking face generation by adversarially disentangled audio-visual representation. AAAI 2019.
High-Level Representations.
video generation tasks by using an encoder-decoder structure as the main approach.
조건이 주어지면 하이레벨 표현으로 변환해서 이것을 제너레이티브 넷웍에 입력해서 픽셀이 이동할 것으로 예상되는 위치에 대한 분포를 출력한다.
[31] Learning to generate long-term future via hierarchical prediction. ICML 2017. body landmark.
[14] Learning hierarchical semantic image manipulation through structured representations. NIPS 2018.
[34] Hierarchical long-term video prediction without supervision. ICLM 2018.
[15] Inferring semantic layout for hierarchical text-to-image synthesis. CVPR 2018.
Attention Mechanism
[20] Effective approaches to attention-based neural machine translation. EMNLP 2015.
[26] Anatomically-aware facial animation from a single image. ECCV 2018.
[37] Self-attention generative adversarial networks. CoRR 2018.
[22] Da-gan: Instance level image translation by deep attention generative adversarial networks. CVPR 2018.
[36] Attngan: Fine-grained text to image generation with attentional generative adversarial networks. CVPR 2018.
[26] 얼굴 표정을 액션 유닛 어노테이션으로 부터 생성했다. 기본 간 구조 대신 어텐션 마스크와 RGB 컬러변환을 생성하는 제너레이터를 사용했다. 어테션 마스크는 픽셀마다 밝기를 정의한다. 최종이미지에 입력 이미지 픽셀이 얼마나 기여하는지 결정하기위해.
이 페이퍼에서는 이 어텐션 방법을 차용했다. 비주얼 변화와 오디오 노이즈에 강인하게 하기위해서.
[10] 가중치 마스크를 로스함수에 통합하는게 리컨스트럭션 성능을 향상할 수 있음을 발견했다. 이 근거에 기반하여 고정한 로스 가중치르 쓰기보다는 어테션 메커니즘에 기반한 로스 가중치를 사용하였다.
Architecture
Audio Transformation network(AT-net) and Visual Generation network(VG-net)
attention-based dynamic pixel-wise loss, regression-based discriminator structure.
Cascade Structure and Training Stragegy
오디오 시퀀스, 이미지 하나, 랜드마크 하나 가 입력으로 들어오면 출력으로 새로운 랜드마크를 생성하고 연이어 이것을 입력으로 하여 새로운 이미지를 생성한다.
이 문제를 풀기 위해 캐스캐이드 구조로 접근했다.
예측된 랜드마크 = AT-net( 입력 오디오, 입력 랜드마크)
예측된 이미지 = VG-net(예측된 랜드마크, 입력 이미지, 입력 랜드마크)
AT-net은 conditional LSTM encoder-decoder 구조이다.
VG-net은 multi-modal convolutional recurrent network이다.
예측하는 동안 AT-net은 오디오 시퀀스와 입력/예제 랜드마크를 입력으로 받아 저차원 얼굴 랜드마크를 예측한다.
예측된 랜드마크, 입력/예제 랜드마크, 입력/예제 이미를 VG-net에 입력으로하여 합성된 새 이미지를 얻는다.
AT-net과 VG-net은 따로 학습된다. VG-net을 티처 포싱으로 학습하기위해서이다. 그리고 에러 누적을 피하기위해서 예측된 랜드마크가 아닌 그라운드 투루쓰로 학습된다.
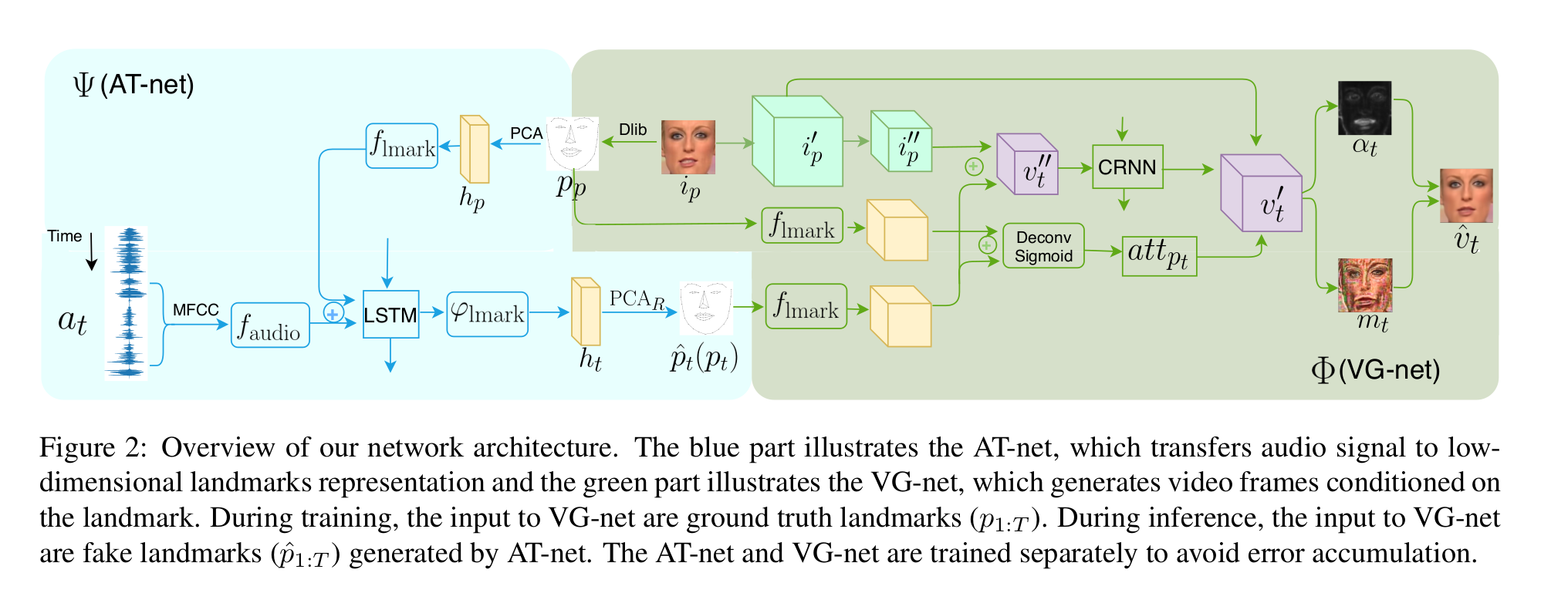
AT-net(Audio Transformation Network)
입력된 오디오는 MFCC로 변환되어 오디오 엔코더에 입력된다.
타겟 인물의 입력/예제 랜드마크는 PCA로 분해하여 가중치를 얻고 랜드마크 엔코더에 입력된다.
출력은 입력 오디오와 대응되는 타겟 인물의 랜드마크의 PCA 성분이다.
오디오 엔코더의 출력과 랜드마크 엔코더 출력은 LSTM을 통과하여 PCA 성분이 출력되고
이 PCA성분은 부스트 매트릭스와 곱해져서 PCA 리컨을 통해 랜드마크로 재구성된다.
부스트 매트릭스는 PCA특징을 살려준다? PCA를 사용하는게 머리의 음직임과 같은 오디오와 상관없는
움직임을 줄여주는 효과가 있다.
VG-net(Visual Generation Network)
[34], [31] 과 유사하다. 특징공간에서 현재 입력 랜드마크와 예제 랜드마크의 거리는 예제 이미지와 생성할 이미지와의 거리를 특징공간에서 표현할 수 있다고 가정했다. 이 특징 공간 거리를 Vt''로 128x8x8크기로 구했다. [34], [31]와의 차이는 엘레먼트 합이 아닌 컨케트네이션으로 바꿔서 입력 프레임의 정보를 더 살린것이고 이것은 경험적으로 선택했다. 즉, 입력 이미지로부터 나온 특징과 예측된 랜드마크로 부터 나온 특징을 컨켓했다.
두 랜드마크로 부터 각각 나온 특징을 입력으로 둘의 차이로부터 어텐션 맵을 생성했다.
어텐션맵, 이미지 특징, CRNN(예측 랜드마크 특징, 이미지특징) 이렇게 3개를 합쳐 128x32x32 특징을 만들어 MMCRNN에 입력으로 넣었다. 그래서 최종적인 결과 이미지를 얻었다. CRNN은 Conv-RNN, residual block, deconv 로 이루어져있다.

Attention-Based Dynamic Pixel-wise Loss
GAN과 encoder-decoder 구조를 사용하는 모델에서 지터링과 아티팩트는 큰문제이다.
이유는 GAN로스 또는 L1/L2로스가 시간 공간에서 지속적으로 변화하는 완벽한 프레임을 거의 생성하지 못한다.

그래서 어테션 로스를 사용했고 [26]에서 사용한방법과 같이 어테션 마스크와 RGB 컬러 변환을 사용했다.
오디오 비주얼 연관없는 부분에 적용하기위해서이다. 예제 이미지에서 오디오와 상관없는 부분은 살린다(1-a).
mt는 모션을 의미하고 mt에서 모션이 있는 부분을 살려서 더해준다.
어테션 마스크의 의미는 예제 이미지에서 움직여야할 위치로 볼수 있고 이 위치가 로스에 집중적으로 공헌되어야하는것으로 간주할 수 있다.

바 알파티는 그리디언트를 없앤 알파이다. 그리고 기본 가중치 베타를 0.5로주었다. 모든 픽셀이 최적화되도록.