The Beautiful Future
Landmark-guided deformation transfer of template facial expressions for automatic generation of avatar blendshapes 본문
Landmark-guided deformation transfer of template facial expressions for automatic generation of avatar blendshapes
Small Octopus 2022. 6. 24. 02:21ICCVW 2019, Kyushu University.
얼굴 마커 없이 RGB-D camera를 이용해서
일반적으로 Blendshap models을 이용해서 페이셜 익스프레션을 아바타로 트래킹하고 리타게팅한다.
예측된 얼굴 표정으로부터 아바타의 key-shpape은 블렌딩된다.
key-shpape을 만들어 내는것은 전문적인 기술이 필요하여 어렵다.
그래서 블렌드셰입에 기반한 리타케딩 기술은 제한적으로 이미 만들어진 블렌드셰입 아바타에 사용될수 있지만 쉽지않다.
어떤 아바타로부터라도 realistic key-shape을 자동으로 만들어낼수 있는 기술에 대해서 설명한다.
사용자는 타겟 아바타와 소스 블렌드 셰입의 적은양의 대응 버텍스만 지정하면
생선된 타겟의 key-shpae은 소스 블렌드셰입에 직접 맵핑된다.
이렇게되면 캡쳐된 얼굴 모션은 쉽게 어떤 아바타에게도 리타겟팅될수 있다.
심지어 타겟 아바타가 모양이 많이 달라도 된다.
SOTA mesh deformation transfer와 비교한다.
Notations
M: 3D mesh, pair of list (V, F)
V: list of 3D vertices, {v1, ...., vn}
F: list of faces, {f1, ..., fn}
vi: (x, y, z)
fi: (idx1, idx2, idx3), triangular face
Bi: a key-shape of an avatar, i=0,...,n. B0 is neutral expression.
wi: weight of key-shape

source model은 neutral expression mesh와 몇개의 key-shape으로 구성된다.
avatar model은 단하나의 neutral expression mesh만을 가진다.
Polygon deformation
3D affine transformation으로 face 변환을 나타낸다.
affine-transformation은 rotation, scale, shear를 담고 있는 3x3 매트릭스 T와
이동변환 3x1 벡터 d로 표현된다. 즉 affine-transformation 매트릭스는 3x4이다.
어느 face fi = (v1, v2, v3)에서 폴리곤의 회전을 표현하기위해 face면과 오쏘고날한 벡터 v4을 생성할 수 있다.

source model에서 avatar model로 deformation을 transfer하는 문제를 정의한다.
대응하는 face 간 affine transform들의 차이를 최소화 하면 우리는 facial deformation을 트렌스퍼할수 있다.

S는 source 모델에서, T는 target 모델에서
S와 T는 neutral shape에서 하나의 key-shape으로 변환하는 affine-transform의 선형 파트이다.
S는 이미 알고 있고 avatar model의 T와 d를 찾는 것이 목표이다.
p(vi)는 폴리곤 인덱스 리스트인데 버텍스 vi가 공유하는 모든 폴리곤이 해당된다.
Tjvi+dj = Tkvi+dk 수식의 의미는 vi가 속한 모든 폴리곤의 변환 Tk, dk에 의해서 변환 되었을때
모든 변환이 같게되는 Tj, dj의 변환과 같아져야 한다는 의미이다.
|F|는 avatar의 모든 폴리곤 수이다.
||.||F 는 Frovenius norm이다.
face의 수와 vertices의 수는 source model과 avatar model에서 다르다.
si는 source model의 face index이다.
ti는 avatar model의 face index이다.
si 와 fi 서로 대응하는 쌍이다. (si, fi)
semi-automatic 방법으로 (si, fi)을 구할수 있는데 4.2에서 설명한다.
avatar mesh의 shape, density, topology에 따라서 위 constrained optimization 식은 풀기 비효율적이고 어려울수 있다.
그래서 [17] Deformation transfer for triangle meshes. SIGGRAPH 2004. 에서 설명한 것과 같이 재정의한다.
(v1, v2, v3)를 가지는 k번째 face가 있고 이 face에 대한 변환 Tk가 있다면
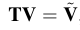
로 쓸수 있고 여기서 V와 ~V는 아래와 같이 정의되는 3x3 matrices 이다.
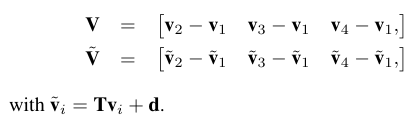
이 수식들로부터 폴리곤 affine deformation 의 컴퍼넌트 T는 아래와 같이 vertices coordinate로 표현 될수 있다.

새로운 변수 ~v1,...,~vn에 따라 아래와 같이 재정의 된다.

avatar mesh의 vertices를 움직임으로써 affine transformation은 source mesh에 가까워진다.
avatar vertices 이동하여 모든 faces의 affine transformation구성 요소가 source 메시의 affine transformation 구성 요소에 가까워지도록하면 local shape과 근접성을 유지하면서 avatar는 변형된다.
이 vertex 기반 접근 방법을 평가방법에 사용한다.
Proposed method
[17]에서 제안한 방법을 확장한다.

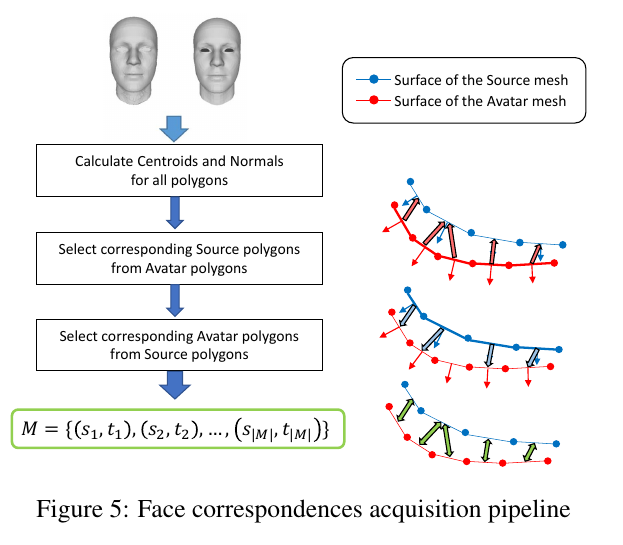
첫번째 스텝은 face correspondences를 찾는 것이다. (초록박스)
이를 위해 avatar mesh를 source mesh에 맞게 스케일한다.
facial landmark에 기반하여 mesh 조직을 유지하며 avatar mesh을 source mesh로 변형한다.
정밀한 3D 변형을 통해 source mesh 와 warped target mesh를 overlay하여 face correspoindences을 구할 수 있습니다.
두번째 스텝은 deformations을 transfer하는 것이다. (살색박스)
여기서 deformations는 source model의 neutral shape과 key-shapes 간에서 구해진 것이다.
affine transform의 선형 컴퍼넌트을 대응하는 face에 전달한다.
vertices의 움직임으로 translation part를 정의한다. 이것은 각 avater face의 affine transform 구분하게 해준다.
모든 key-shapes을 생성한다.
Re-scaling

source meshes의 바운딩 박스의 싸이즈, avatar meshes의 바운딩 박스 싸이즈 비율로 리스케일한다.
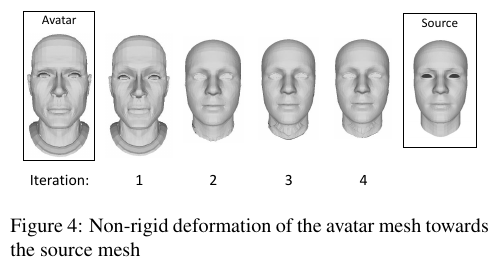
Non-rigied deformation
correspondences mesh을 찾기위해 avatar mesh을 source mesh로 deform한다.
transformed avatar 의 vertices 을 변수로 3개의 constrained minimization problem을 푼다.
첫번째 코스트 함수

adj(i)는 i번째 face에 인접한 faces의 인덱스들이다.
Ti는 i번째 face의 affine transformation에서 선형파트이다.
하나의 face의 affine transform과 인접한 face의 affine transform은 비슷해야한다.
두번째 코스트 함수

I 는 identity matrix이다. Ti들은 I와 가까워야한다.
최대한 회전, 스케일, shearing 변형이 안이루어져야한다.
세번째 코스트 함수
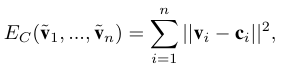
ci 는 vi와 가장가까운 source model의 한 버텍스이다.
avatar model과 source 모델은 가까워 져야한다.
vi의 노말벡터와 ci의 노말벡터는 90도 안에 들어오게 강요된다.
이 각도를 고려함으로써 윗입술 아랫입술과 같이 위상학적으로 먼 지역이 구분 가능해진다.
위 세 코스트 함수에 가중치줘서 합을 최소화하도록한다.
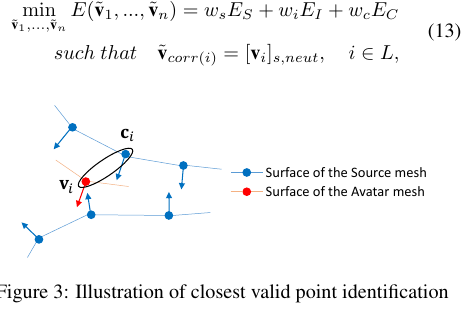
위 그림 처럼 vi에 가까운 버텍스는 아래에 있지만 각도 조건은 위에 있는 버텍스가 만족되기때문에 위가 선택된다.
[vi]s,neut는 neutral source model에 있는 버텍스를 의미한다.
L은 source mesh에 있는 얼굴 랜드마크 인다이스들 리스트이다.
corr(i)는 i번째 source vertex에 대응하는 avatar vertec index이다.
위 수식을 최적화하기위해 facial landmark는 사용자로부터 주워져야한다.
우리는 51개의 dlib에 있는 facial landmark를 사용했다. 눈, 눈섭, 코, 입.
의미론적으로 같은 버텍스를 잘 연결해줘야한다. 아바타 메쉬의 레졸루션이 부족하다면 아바타메쉬를 업셈플링해줘서 설정한다.
최적화를 4번 돌렸고 각 코스트의 가중치를 변화하면서 했다.
첫번째 ws=1, wi=0.1, wc=0
나머지 ws=1, wi=0.001, wc=1
Matching
변경된 아바타 메쉬로부터 페이스 코레스폰더스를 구할수 있다.
변경된 아바타를 소스에 정렬했다.
1. 두 모델에서 모든 페이스의 중심과 노말 벡터를 계산했다.
2. 모든 아바타 메쉬를 가장 가까운 소스 메쉬와 매칭했다.
조건은 노멀벡터간 각도가 90도 이하일때
3. 반대로 소스에서 아바타로 같은 계산을 했다.
중심 거리가 가장 가까운 순서로 노멀벡터가 90 이하 차이를 가지는 페이스를 대을 페이스로 지정했다.
둘 중 페이스 개수가 더 많은 쪽에 중복 대응 페이스가 many to one...

si: source face index
ti: avatar face index
|M|: the number of face of
Deformation transfer
아바타 모델의 키셰입을 생성하기 위해 페이스 대응을 사용했다.
소스 모델의 뉴트럴과 다른 표정 사이의 차이를 뉴트럴 아바타 모델에 전달했다.
이 변형 전달은 랜드마크에 가이드 된다.
Polygon deformation transfer
아래 식은 폴리곤 디포메이션 프랜스퍼 코스트 함수이고 위에 나왔던 수식과 M을 페이스 페어로 사용하는 것이 다르다.
[17]에서는 오직 이 디스플레이스먼트만 사용했는데 우리는 두가지 추가적인 코스트 함수를 사용한다.

Landmark guided deformation transfer
성공적인 표정 전달을 보장하기 아래 코스트 펑션을 제안한다.
심지어 선형변환에 조작당하지 않는 메쉬들 조차도.
우리는 선택된 얼굴 랜드마크의 모션 사용하는것을 제안한다.

Lk는 소스메쉬에 있는 랜드마크 인덱스 리스트
corr(i)는 i번째 소스 메쉬에 대응하는 아바타 메쉬에 있는 랜드마크 인덱스
ui, ~ucorr(i)는 뉴트럴 표정과 현재 표정의 사이의 디스플레이스먼트 벡터 각각 소스와 아바타 메쉬.
[v]는 메시에 있는 포인트 s 소스 t 아바타 exp 표정 neut 무표정
Ak, Rk 는 3x3 매트릭스로 래드마크의 움직임 조절을 허가한다.
얼굴 파트의 크기와 방향은 선택된 아바타에 따라서 매우 다르다.( 말 얼굴과 사람얼굴)
그래서 얼굴의 파트를 6개로 나눈다. 오른쪽 눈썹, 왼쪽 눈썹, 코, 오른쪽 눈, 왼쪽 눈, 입
각 파트의 크기와 방향을 측정해서 일관되게 랜드마크 모션의 양과 방향을 조절한다.
각 파트의 방향을 측정한다.
Lk로 랜드마크가 속하는 얼굴 파트로 6곳으로 나눈다. k = 1~6
각 그룹에서 얼굴 파트의 방향을 가장 잘 계산할 수 있는 랜드마크를 선택한다.
그리고 이것을 L'k로 표기한다.
아래의 코스트 함수를 최소화하는데, 노말 벡터 nk가 근사적으로 모든 라인 에 수직이 되도록 최소화한다.
모든 라인은 L'k에 있는 모든 랜드마크 사이에 있는 라인이다.
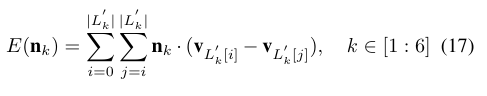
k번째 페이스의 방향벡터 nk로 부터, 우리는 nk를 z축에 얼라인하는 Rk,s와 Rk,t를 계산할 수 있다.
이 회전 행렬은 각각 독립적으로 6개의 얼굴 파트마다 계산된다.
얼굴 각 파트의 크기를 측정하기위해, 우리는 첫째로 얼굴 파트를 z축에 정렬하기위해 회전행렬 Rk,s와 Rk,t를 사용했다.
그 다음 3D bounding box를 구하고 소스와 아바타의 크기를 ax,s ay,s az,s 그리고 ax,t ay,t az,t를 각각 구했다.
size ratio Ak를 아래와 같이 구했다.
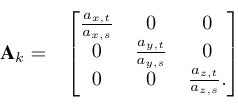
입 파트는 중립 아바타 메쉬만으로는 움직임의 범위를 측정할 수 없는 경우이다.
이경우 z 방향 비율은 1로 고정하고 x방향은 bounding box 크기 y방향은 코의 하단과 아랫입술의 중심 사이의 거리를 사용하여 y 방향의 비율을 계산했다.
소스 랜드마크를 리싸이즈 및 정렬된 아바타 얼굴 부분의 좌표계로 워핑함으로써 신뢰성있게 랜드마크 모션을 소스에서 아바타로 전달할수 있다.
아바타 랜드마크 모션 벡터 ~ucorr(i)는 소스 ui에 AkRk이 곱해져서 구해진다.(AkRkui)
Optimization
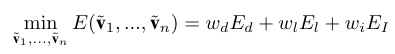
wd =1, wl=100, ws=10, wi=1 이다.
Ed: polygon cost function
El: landmark cost function
EI: Idendity cost fuction
Experiment
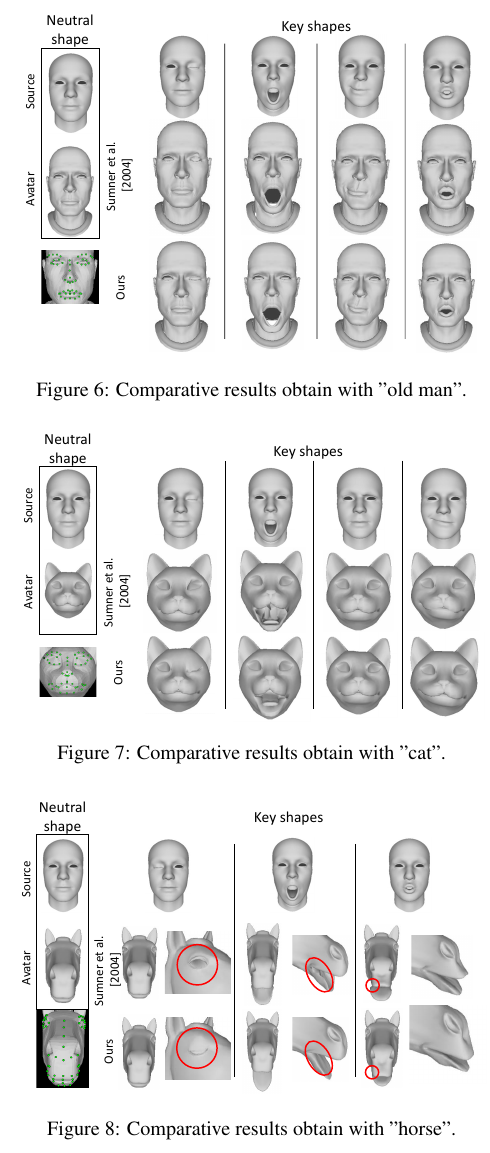
완전히 형태가 다른 몇몇 아바타를 이용해서 제안한 방법을 검증했다.
[17]Summer와 비교했다.
턱 랜드마크는 사용하지 않았고 얼굴 랜드마크만 사용했고 충분했다.
사람과 많이 유사한 아바타에서 랜드마크를 선택할때에는 정밀하게 선택한 반면
형태가 많이 다른 아바타에서는 근사화된 위치를 선택할 수 밖에 없다.
fig6과 같이 사람과 유사한 경우는 [17]과 큰 차이를 보지 못했지만 fig7,8에서는 차이가 있다.
큰 차이는 눈 주변에 서 일어난다. 완벽한 페이스 대응이 일어나지 않아서이다.
fig9는 보인다.
[20] Augmented blendshapes for real-time simultaneous 3d head modeling and facial motion capture. CVPR 2016.
을 이용해서 리얼타임 데모를 만들었다.