
The Beautiful Future
ThunderNet 본문
중국 국방 기술 대학교, 메크빌 페이스 플러스플러스
ICCV2019
모바일 투스테이지 디텍터
이전 백본의 문제점을 보완하며 가벼운 백본 디자인을 제안한다.
매우 가벼운 RPN과 검출 헤드를 이용한다.
Context Enhancement Module(CEM)과 Spatial Attention Module(SAM)을 디자인 했다.
입력 크기와 백본, 검출 헤드의 비율조정
ARM기반 기기에서 24fps를 달성하였다. 19.2 AP on COCO.
이미지 클래시피케이션에 사용되는 배본을 사용하는데 클래시피케이션과 디텍션은 다르다.
검출은 더 큰 리셉티브 필드가 필요하다.
낮은 레벨 특징이 정확한 위치를 예측하는데 필요하다.
검출기는 크게 원스테이지 검출기와 투스테이지 검출기로 나눠진다.
투스테이지
[27] Faster r-cnn: Towards real-time object detection with region proposal networks, NIPS2015
[4] Object detection via region-based fully convolutional networks, NIPS2016
[16] Feature pyramid networks for object detection CVPR2017
[14] Light-head r-cnn: In defense of two-stage object detector. arXiv: 2017
원스테이지
[24] You only look once: Unified, real-time object detection. CVPR2016
[19] Ssd: Single shot multibox detector. ECCV 2016
[25] Yolo9000: better, faster, stronger. CVPR 2017
[17] Focal loss for dense object detection. ICCV2017
투스테이지는 RPN과 검출 헤드로 이루어져잇다. ROI warping, R-CNN subnet.
RPN이 ROI을 생성하면 검출헤드에서 리파인된다. 소타 투스테이지는 검출헤드가
굉장히 크다(10GFLOPs [27][10][4][16][2])
원스테이지는 디텍션 헤드가 따로 필요없다는 장점이 있지만 ROI가 없어서 결과가 거칠다.
라이트웨이트 디텍터
[11]MobileNet-SSD, Mobilenets: Efficient convolutional neural networks for mobile vision applications, arXiv 2017.
[28]MobileNetV2-SSDLite, Mobilenetv2: Inverted residuals and linear bottlenecks, CVPR2018.
[31]Pelee: a real-time object detection system on mobile devices, NIPS 2018.
[13]Tiny-DSOD, Tiny-dsod: Lightweight object detection for resource-restricted usages, arXiv 2018.
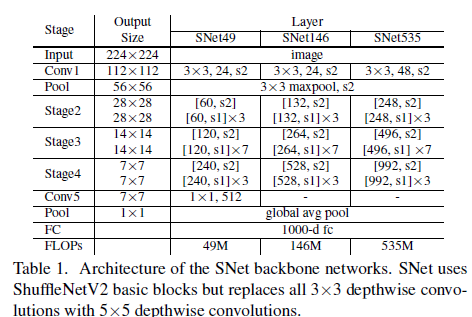
SNet을 백본으로 제안
디텍션 헤드로 Light-Head R-CNN의 디자인을 따른다.
RPN과 R-CNN을 더 줄인다.
Tiny-DSOD[13]의 42%연산량이지만 성능은 더 좋다.
DetNet[15]은 백본을 특별히 디자인했다.
FPN은 800pixel 인풋을 사용한다.
썬터넷은 입력 크기 320x320x3을 사용함.
작은 백본에 큰입력, 큰 백본에 작은 입력, 둘 다 최적이 아니다.

3x3 depth-wise 보다 5x5 depth-wise가 좋다.
3x3 depth-wise 두개 넣는 것 보다 5x5 depth-wise가 좋다. 디텍션에서는 안좋구 클래는 조금 좋아짐.
[23]
[14]
위 두 논문은 넓은 리셉티브 필드의 중요성을 말함.
로우 레벨 특징은 위치정보, 하이 레벨 특징은 클래시피케이션 정보에 좋다?
실험적으로 큰 백본일 수록 클래시피케이션 보다 위치화에 어려운것을 보았다.
셔플넷12은 320 입력에 리셉티브필드가 121로 제한적이다.
셔플넷2와 모바일넷2는 초반 특징이 부족하다.
엑셉션은 작은 연산량 예산에서 하이레벨특징을 뽑기어렵다.
그래서 셔플넷2을 기반으로 SNet을 설계하게되었다.
셔플넷2의 3x3뎁스컨브를 5x5로 바꿨다. 121리셉티브에서 193리셉티브로 늘어났다.
SNet49, SNet535, SNet146 세가지 모델을 실험.
SNet535, SNet146 에서 Conv5를 제거하고 초반 레이어네 채널을 더 추가했다.
SNet49에는 Conv5를 512 채널로 줄이고 초반 레이어에 채널을 추가했다.
원래 Conv5은 1024 채널을 가지기 때문에 연산량이 너무 많다.
RPN의 3x3 conv를 5x5뎁스와이즈세퍼러블로 교체 256채널.
Light-Head R-CNN을 더 가볍게 바꿈.
5스케일 32, 64, 128, 256, 512. 5 aspect ratios 1:2, 3:4, 1:1, 4:3, 2:1 앵커.
Light-Head R-CNN은 RoI 와핑전에 10x7x7의 얇은 특징맵을 출력,
ThunderNet은 더 작은 입력과 다른 백본을 가지기 때문에 작은 특징 맵을 가지고
불필요한 연산을 줄이기위해 5xPxP 출력을 한다.
PSRoI align 선택하여 채널을 5로 줄였다.
PSRoI align으로 부터 나온 특징은 245-d 이기때문에 1024-d fc layer을 R-CNN subnet으로 사용하였다.
Light-Head R-CNN은 Global Convolutional Network(GCN)을 사용하여 얇은 특징맵을 출력하였다.
이 방법은 리셉티브필드를 매우 키우지만 연산량이 너무 많아서 버렸다.
넷은 작은 리셉티브필드와 문맥정보를 압축하지 못해 위협받는다.
이 이슈를 해결할 방법은 FPN이 일반적인데, 많은 여분의 conv와 멀티 검출 브랜치가 필요하다.
그래서 CEM 모듈을 디자인했다. 다양한 스케일의 지역특징과 글로벌 문맥 정보를 어그리게이션 하는것이다.
C4, C5, Cglb 세개의 문맥정보를 합친다.

Spatial Attention Module(SAM)
ROI warping 할때 포함된 배경은 적고 전경은 많기를 바라지만
썬터넷은 작은 백본과 작은 입력 이미지를 사용하기때문에 제대로된 특징 분포를 배우기 어렵다.
RoI warping 전에 특징에 재가중치를 줄수 있는 SAM을 설계하였다.
Fsam = Fcem * sigmoid( dsconv5(conv1(Frpn))
배경 전경 구분에 강점이있다. SAM이 여분 그래디언트(R-CNN subnet to RPN)활성화하여 RPN학습 안정성을 준다.
Online hard example mining [29]
Soft-NMS [1]
Cross-GPU Batch Normalization (CGBN) [22]
'논문' 카테고리의 다른 글
| Detailed Expression Capture and Animation (0) | 2022.05.21 |
|---|---|
| Structure-from-Motion Revisited (0) | 2022.02.10 |
| Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression (0) | 2021.02.20 |
| BlazePose: On-device Real-time Body Pose tracking (0) | 2021.02.17 |
| FrankMocap: Fast Monocular 3D Hand and Body Motion Captureby Regression and Integration (0) | 2021.01.28 |
