
The Beautiful Future
3D Shape Regression for Real-time Facial Animation TOG2013 본문
얼굴 검출기 없이 주어진 카메라에 얼굴이 크기 범위로 나온다는 가정으로 학습되고 사용되어질수 있게 알고리즘이 설계되었다.
User-specific face model
-- 15 rigid motion
yaw: -90, -60, -30, 0, 30, 60, 90
pitch: -30, -15, 15, 30
roll: -30, -15, 15, 30
-- 45 non-rigid motion
yaw: -30, 0, 30
mouth strech, smile, brow raise, disgust, anger,
squeeze left/right eye, jaw left/right, grin,
chin raise, lip pucker, lip funnel, cheek blowing, eye closed.
User-specific Blendshape Generation
FaceWarehouse contain 150 individuals with 46 FACS blendshapes.
11K mesh vertices x 50 identity knobs x 47 expression knobs.

카메라 내부 파라미터는 알고있다고 가정, User-specific face image가 주워졌을때
3D 모델의 vertex 사영과 2D 이미지 랜드마크 사이의 거리를 coordinate-descent method로 최적화.

1. for each input image, find Mi, Widi, Wexpi.
2. refine Wid, which should be same for all images. (fixing Mi and Wexp,i)
모든 이미지의 한 사람을 위한 Wid를 찾기위한 최적화식

위 두 과정이 수렴할때 까지 반복된다(3번 정도면 수렴). Yang et al. 2011의 알고리즘을 써서 버텍스 인덱스를 알맞게 업데이트 해준다. Wid가 구해지면 Expression Blendshape을 구축할 수있다. FaceWarehouse에 있는 표정모드 중 47개를 사용. di는 i만 1인 원핫 벡터이다.

Training Set Construction
3D shape regressor학습을 위한 3D landmark 학습셋이 필요하다.
최적화 과정을 통해서 학습셋을 만든다. 이제 blendshape alpha 값(expression coefficent)을 찾아내는 문제로 변형되었다.

레귤러 텀으로 사전에 정의된 표정들에 대해서 어느정도 정답이 있다고 볼수 있다.
Li el al 2010에서 사용되었던 a*의 값과 유사해야한다.

위 두가지 텀을 합쳐서 아래와 같은 수식을 풀어내면 된다.

이 식을 coordinate-descent method 방법을 사용하여 두 파라미터을 번갈아 고정하여 반복 최적화했다.
a의 초기값을 a*로 하였다.
M을 계산 할 때는 POSIT algorithm을 사용하였다.
a를 계산 할 때는 BFGS solver기반의 gradient projection algorithm을 사용하였다. (0~1사이로 제한)
Wreg의 값을 10으로 고정하여 사용하였다.
매 최적화 반복마다 버텍스의 인덱스를 업데이트 하였다.
카메라 좌표계의 3D mesh을 아래식으로 계산할 수 있다. 그리고 3D landmark를 뽑아낸다 {S_i^o}.

Data Augmentation
3D shape을 카메라 코디네이트에서 x,y,z로 translation했다. 이미지당 m-1개의 부가적인 shaped얻을 수 있게,
원본 포함 이미지당 m개씩(Sij), 1<= j <= m. S_i^o = Si0 이된다.
이미지를 직접 변화 해서 학습하기 보다 M변환 매트릭스에 저장을 해서 원본으로 복원 될수 있게했다.
즉 3D shape 이동변환과 이에 대응하는 M을 같이 저장했고 대응하는 이미지는 그대로이다.
Temperal Inital Shape Dataset
실시간으로 동작할때 우리는 이전 프레임의 값으로 부터 초기 3D shape을 시작할 수 있기때문에 학습셋에도
이전 프레임에서 계산된것 같은 효과의 3D shape으로 쌍을 지어줬다(S_ij^c).
60개의 원본 3D shape중에서 G개의 가장 유사한 shape을 선택하고 (Sig, 1 <= g <= G)
Data Augmentation 스텝에서 구해진 것중에서 랜덤하게 H개를 선택했다 (Sigjh, 1 <= h <= H).
이 과정은 총 GH개의 초기 3D shape을 만들어준다. Sij를 위해서. 각 학습 샘플은 아래 수식과 같이 나타내어진다.

실제로 사용된 n = 60, m = 9, G = 5, H = 4 이다.
Camera Calibration
일반적인 캘리브레이션 대신 사용자 설정 이미지로부터 캘리브레이션을 할 수 있는 방법.
가장 심플한 핀홀 모델을 가정, fx=fy=f, cx=c_imgx, cy=c_imgy, shear=0 그럼 f만 구하면된다.
f 값을 조절하면서 User-specific Blendshape Generation 생성 방법으로 fitting 해보면서 적은 값이 나오는 f를 사용할 수 있다.
이 논문에서 만족할만한 결과를 보여줬다.
Face Tracking
3D Shape regression 결과로 부터 변환 M과 expression coefficient를 뽑는 방법.

이 과정에서는 버텍스를 업데이트 할 필요가 없는데, 3D Shape regression 결과가 이미지 위에 보이는 좌표가 아니라
실제 3D의 좌표라고 생각하면 되기때문이다. 그래서 실제로 내부파라미터(Q)도 안곱해지고 있고 vk, k는 고정 인덱스.
animation prior GMM for temporal coherence in tracking, Weise et al 2011과 같은 방법.

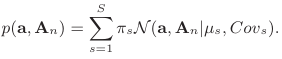
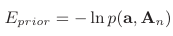

Wprior는 1로 사용됨.
1. 이전 프레임에서 계산된 a 값을 초기값으로 사용하여 regression된 S와 Blendshape S 사이의 M을 계산.
이문제는 3D registration문제이고 SVD on cross-covariance matrix [Besl and McKay 1992] 의 방법으로 품.
2. 이젠 M을 고정하고 expression coefficient를 위해 iterative gradient solver로 최적화를 품.
Eprior에 대한 사전 gradient를 풀어놨음. gradient projection algorithm 기반 BFGS solver로 품 0~1 사이로 제한하면서.
위 두 스텝을 수렴할때까지 반복, 2번이면 충분했다.
Evaluation and Comparison
수작업으로 2D위치가 어노테이션된 키넥트에서 구해진 3D값과 비교하였다. 키넥트 뎁스와 프로젝션 매트리스을 사용.
오차는 1센티 이하였다.
2D regression 결과에 있어서 Face alignment by explicit shape regression과 optical floaw 기반 Face transfer with multilinear models 두 방법과 정성적으로 비교.
'논문' 카테고리의 다른 글
| Attention Mesh: High-fidelity Face Mesh Prediction in Real-time (0) | 2022.12.28 |
|---|---|
| COMA (0) | 2022.09.23 |
| Facial Retargeting with Automatic Range of Motion Alignment (0) | 2022.08.20 |
| Realtime Performance-Based Facial Animation (0) | 2022.08.14 |
| Multi-view 3D Reconstruction Software (0) | 2022.08.09 |


