
The Beautiful Future
taobao Text/Speech-Driven Full-Body Animation 본문
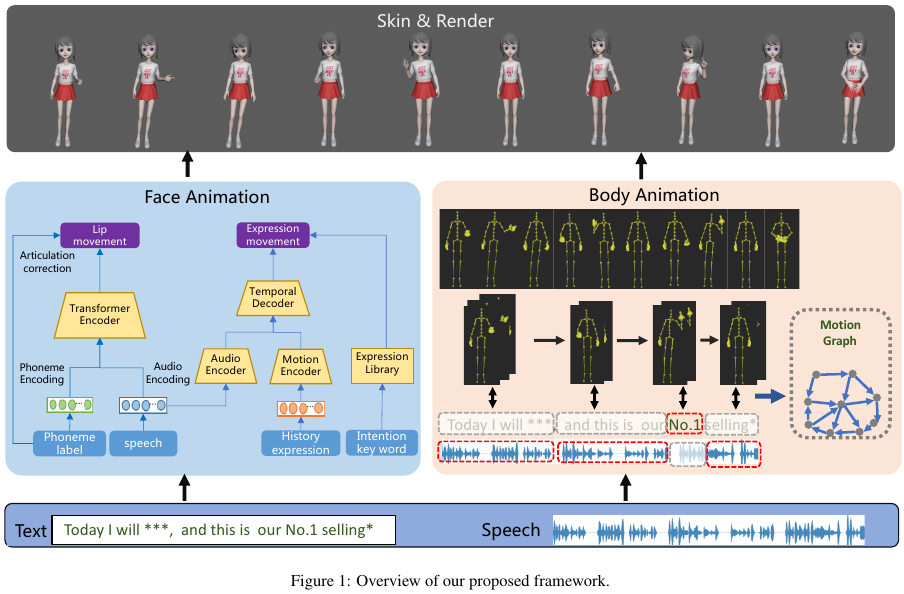
divided into two major parts including lip movements in the lower face and diverse expressions in the upper face.
multi-pathway framework to generate movements of two facial parts respectively.
use the facial motion capture device to collect 3 hours human talking data with diverse expressions.
record both video data as well as 3D face parameter sequences under the definition in ARKit with 52 blendshsape.
Lip movement generation
cross-modal transformer encoder to utilize both speech and textual information.
for the modeling of txtual information, we extract phoneme alignment annotation according to
the speech and textual scripts by time alignment analyzer such as Montreal Forced Aligner toolkit.
Ph = {pht}, t=1,...,T.
concatenates MFCCs and MFB features denoted as Au = {aut), t=1,...,T.
transformer encoder takes a sequence of concatenated phoneme embedding and audio features as input
with a window size of 25 fps, whose duration is 1 second.
the transformer encoder can effectively model the temporal context information
with a multi-head self-attention mechanism across different modalities.
Objective for Lip consists of two terms, including a shape term and motion term.
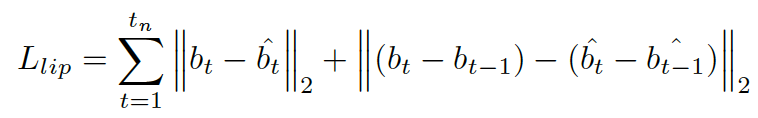
bt is 3D facial parameters.
articulation correction by given phoneme label. the mouth should be closed during the pronunciation fo b/p/m.
Expression generation
the facial expression in the upper face mainly lies in the movements of eye and eyeborws.
which are related to speech rhythm and intention of the speaker with longer-time dependencies.
- rhythmic expression movement by learning-based framework.
an audio encoder to model the current speech signals as well as
a motion encoder to model the history expressions.
a transformer decoder is adopted to predict the final expr movements according to audio and history motion info.
since synthesizing expression is a one-to-many mapping, use SSIM loss to explore the structural similarity between the predicted expression and ground truth.
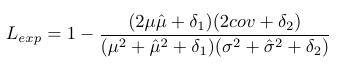
mu adn sigma are the mean and standard deviation of generated 3D facial parameter sequence.
cov is the covariance.
- intention-driven facial expression based on the semantic tags
semantic tags are extracted from textual scripts via sentiment analysis.
semantic tags include happiness, sadness, emphasis, fear and etc.
Actors are asked to performers more than 50 intention-based expression according to the semantic tags.
fusing the generated rhythmic expression with the proper intention-driven expression triggered by the semantic tags.
integrate the lip movements to form the final expressive and diverse facial animation.
Body Animation
a graph based on an existing motion database.
motion segments according to the features of the given text/speech.
Motion graph construction
semantic motions: 24 kinds of actions( such as numbers, orientations, and special semantics)
non-semantic motions: declarative actions( upper body movements of standing, body center shifting movements, foot stepping movements)
node denotes a motion segment, edge denotes the cost of transition between two nodes.
obtain graph nodes
dividing each long sequence in database to obtain many small motion segments
dividing points: local minima of the motion strength,
build graph edges
connection relationship between motion segments
transition cost based on the distances between salient joint positions and movement speeds.
a graph edge can be created if the transition cost between adjacent nodes is below a threshold sigma.
semantic motions in the motion graph need to be obtained manually.
graph-based retrival and optimization
rules: special semantic text and phonetic rhythm
given a section of text/speech P, analyze the input, divide it into many phrases (Pi, i=1, ..., n).
(Pi, i=1, ..., n) according to text structure and find the special semantic text in the section.
meaningful motion segments, the semantic text and similarity of rhythm between motion segment and speech phrase.
motion and phonetic rhythm are obtained by motion strength
motion str: Dancing to music. Advances in Neural Information Processing Systems, 32, 2019.
phonetic rhythm: librosa (Audio and music signal analysis in python. In Proceedings of the 14th python in science con-
ference, volume 8, pages 18–25. Citeseer, 2015.)
to assign a motion node to each text/speech phrase so that the cost is minimized
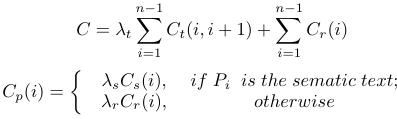
Ct( i, i + 1) is the transition cost between adjacent nodes.
Cp(i) accounts for the loss of Cs and Cr.
Cs(i) special semantic text.
Cr(i) phonetic rhythm.
'논문' 카테고리의 다른 글
| Face2Face (0) | 2023.03.03 |
|---|---|
| Facial Expression Retargeting from Human toAvatar Made Easy (0) | 2023.01.26 |
| Attention Mesh: High-fidelity Face Mesh Prediction in Real-time (0) | 2022.12.28 |
| COMA (0) | 2022.09.23 |
| 3D Shape Regression for Real-time Facial Animation TOG2013 (0) | 2022.08.27 |



